Data Lakehouse - is it the new Holy Grail?
During the past 1-2 years, there has been a lot of excitement around Data Lakehouses (or Data Lake Houses). The term is a combination of "Data Lake" and "Data Warehouse".
What really is a Data Lakehouse and does it really represent anything new?
Bill Inmon is named by Computerworld as one of the ten people that most influenced the first 40 years of computer industry and he is known as "the father of the data warehouse". During a talk at Databricks' Data + AI Summit 2021, he said that Data Lakehouses will "present opportunities like we've never seen before". That is very heavy support, because no doubt Bill Inmon is still a thought leader within Data Management.
"I believe the lakehouse is going to unlock the data that is there and gonna present opportunities like we've never seen before."
Bill Inmon
Not everyone is a fan of the term Data Lakehouse though. Snowflake argues that the Data Lakehouse is nothing new, but what they already have been supporting for years with their platform. In fact, it was one of Snowflakes' customers, Jellyvision, that coined the term Data Lakehouse in 2017 to describe the Snowflake platform. Snowflake therefore means they are the "original Data Lakehouse", although they call their technology Data Cloud instead. So, Snowflake's reluctance about the term Data Lakehouse is more about branding, not about the technology.
So what exactly is a Data Lakehouse? Good question - we'll get back to that later.
History
Before going into definition, let's look into the history.
| Era | Description |
|---|---|
| 1980s - Data Warehouses | Data Warehouses came up as a solution against Data Silos. They address the issues of data modeling, archiving data, offloading the source systems, "a single version of the truth", security and data governance. |
| 2010s - Data Lakes | Many Data Warehouse projects ran into problem because of complex Data Modeling. Another problem with Data Warehouses is that they work well for structured data, but not so well for unstructured data. Storage is usually also expensive for the databases. This led to the era of Data Lakes, where data is stored with little or no data modelling in files on cheap storage. |
| 2020s - Data Lakehouse | Data Lakes kept growing out of control and often turned into "Data Swamps". Also many organizations needed to build a Data Warehouse on top of their Data Lake. The Data Lakehouse was born as a way to get the best features of Data Warehouses and Data Lakes. |
Are Data Lakehouses here to stay or will they soon be replaced by something new? Will they replace Data Warehouses? Good questions - let's get back to those later.
Data Lakehouse Definitions
Depending on who you ask, there are different definitions of a Data Lakehouse. Here are two examples:
"A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data."
Databricks
"A data lakehouse is an architectural approach for managing all of your data (structured, semi-structured, or unstructured) and supporting all of your data workloads (Data Warehouse, BI, AI/ML, and Streaming)"
Snowflake
In summary, these defitions say:
- Databricks: A Data Lakehouse combines the strengths of data lakes with the strengths of data warehouses
- Snowflake: A Data Lakehouse can handle all kinds of data and workloads (in a single platform)
There is nothing incompatible between these definitions, but we still lack an independent definition (and a Wikipedia description) of the Data Lakehouse.
Another way to explain a Data Lakehouse is to compare it with Data Warehouses and Data Lakes.
| Data Warehouse | Data Lake | Data Lakehouse |
|---|---|---|
| Structured data | Structured, semi-structured and unstructured data | Structured, semi-structured and unstructured data |
| Schema-on-write | Schema-on-read | Mixture |
| Expensive storage | Cheap storage | Cheap storage |
| Good security options | Limited security options | Good security options |
| Data Quality guaranteed (ACID, transaction isolation) | No guarantees of Data Quality | Data Quality guaranteed (ACID, transaction isolation) |
| Less adaptable to change | More adaptable to change | More adaptable to change |
Delta Lake
Now there are different ways to build a Data Lakehouse. Let's start by looking into one of them.
Delta Lake is an open-source platform for building a Data Lakehouse Architecture on top of existing storage systems (for example Azure Data Lake or Amazon S3). It was created by Databricks, but is now a sub-project of the Linux Foundation Projects.
Key features are:
- ACID Transactions - which guarantees data integrity and quality while supporting multiple readers and writers at the same time.
- Schema Enforcement - which ensures data meet quality rules.
- Data Versioning - which enables you to "go back in time" and view earlier versions of tables or rollback changes.
- Massively Scalable - works for huge tables with billions of partitions.
- Support for both Batch and Streaming Data - which enables handling IoT workloads as well as more traditional database workloads
With Snowflake you also get these features, but there is one big difference. Snowflake is a proprietary platform while Delta Lake is open-source.
The data flow with a Delta Lake will typically look something like this:
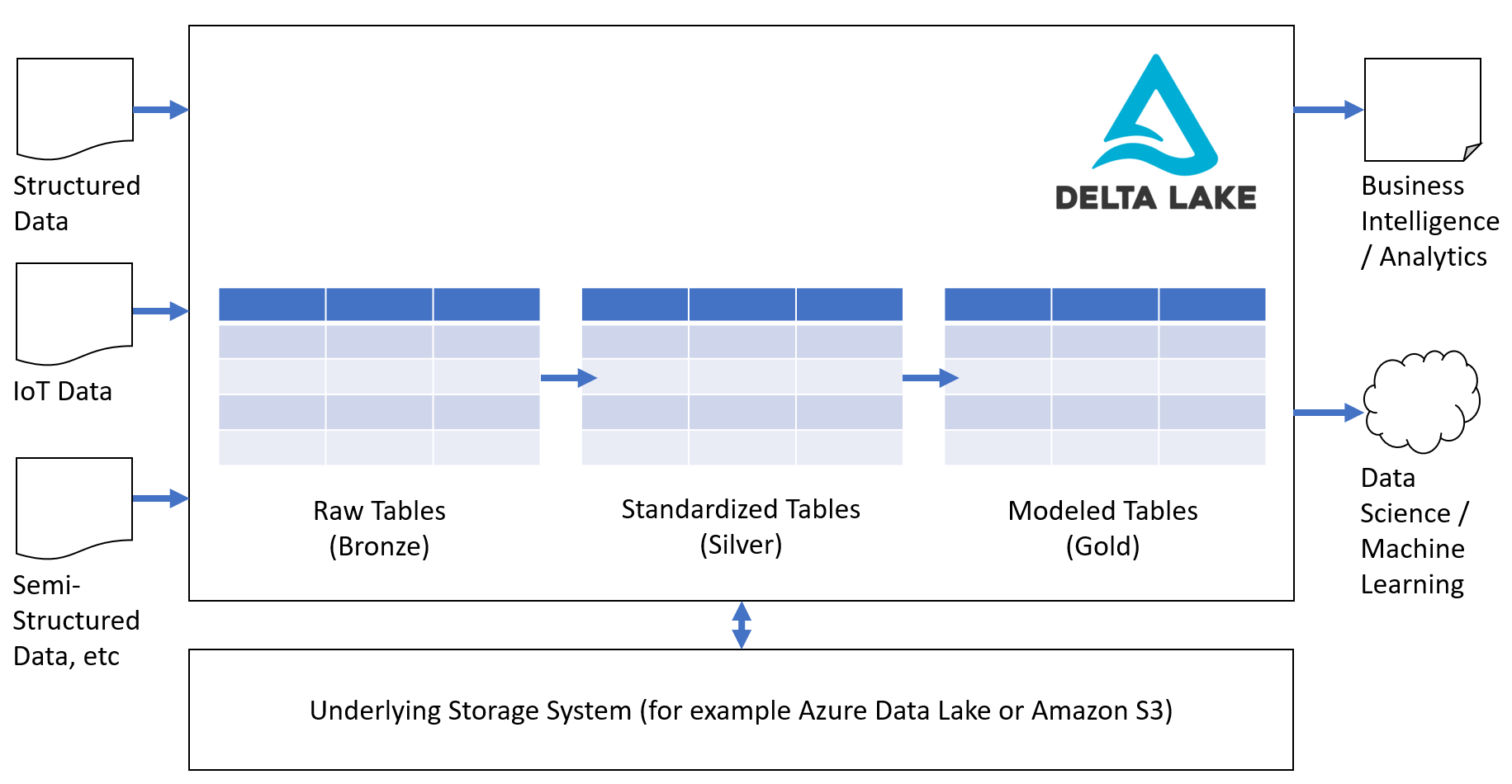
The complete Data Lakehouse
Data doesn't move or get refined by itself inside the Delta Lake. The complete Data Lakehouse is so much more than only storage. It needs also tools and platforms for:
- Loading data from various data sources
- Data transformations and processing
- Running various workloads
- Integrating with popular protocols and APIs
- Authoring of Notebooks and scripts
- Monitoring and auditing
Delta Lake is deeply integrated with Apache Spark (an open-source analytics enginge for large-scale data processing). You can therefore easily take advantage of things such as Spark SQL, Spark Structured Streaming, GraphX as well as tools like TensorFlow and PyTorch. However, you can also work directly with Delta Lakes without going through Apache Spark.
In summary: Delta Lake is to a Data Lakehouse what a relational database is to a Data Warehouse. You also need the ETL/ELT-tools, etc to build the complete solution.
Data Lakehouse platforms
While you surely could put together a complete Data Lakehouse from only open-source platforms and tools, such as Delta Lake, Apache Spark, Apache Hadoop, Kubernetes, etc, it is certainly easier and much less headache to use a commercial platform.
There are a few options.
Databricks
Databricks was founded by the original creators of Apache Spark and Delta Lake. Their main message is "All your data, analytics and AI on one Lakehouse platform" and unsurprisingly their technology is based on Delta Lake and Apache Spark.
The key features of Databricks include:
- Provides an optimized version of Apache Spark
- Provides Delta Lake with some extra optimizations
- Strong Data Science & Machine Learning capabilities
- Data is stored outside of Databricks (for example in Azure or Aws)
- Supports Mixed-Cloud scenarious
Azure Synapse Analytics
Azure Synapse Analytics is a big data analytics service, supporting Apache Spark, Dedicated SQL pools, and Serverless SQL processing.
The key features of Azure Synapse Analytics include:
- Provides open-source Apache Spark
- Provides open-source Delta Lake
- Also has a strong SQL engine that supports most standard T-SQL
- Flexible pricing including a pay-per-query pricing model
- Data is stored inside of Azure
- Integration with other Microsoft services (such as Power BI, Cosmos DB and Azure Active Directory)
Since both Databricks and Azure Synapse Analytics uses Delta Lakes, you can easily share data between them. Tests shows that they are highly compatible.
Snowflake
Snowflake is a modern "data warehouse-as-a-service" that replaces expensive on-premises Enterprise Data Warehouses, as well as supporting a much wider variety of data and workloads.
The key features of Snowflake include:
- Connectors for SQL, ODBC, JDBC, Spark, but internally Snowflake is proprietary technology
- Strong SQL capabilities
- Data is stored inside of Snowflake
- Easy to use and get started
Conclusions
Databricks predicts that the current Data Warehouse architecture will wither and be replaced by the Data Lakehouse.
I am not convinced that Data Warehouses are going away anywhere soon. I believe that in the foreseeable future, Data Warehouses will remain the main architecture for organizations who only focus on Business Intelligence and Analytics. Especially if they wish to keep their data on-premises.
However, the main challenge currently is that of untapped data. Organizations have huge potential gains by using more of their data. This is where traditional Data Warehouses are a bottleneck.
Also Bill Inmon mentioned untapped data at his latest talk at Databricks' Data + AI Summit 2021.
"We found out that there is a wealth of information that hasn't ever been looked at before. I think it's kind of interesting to know that if all you look at is classical structured transaction based data, you're probably only looking at 5-10% of the data in the corporation."
Bill Inmon
So I believe we really are in a technology shift again. From Data Lakes (and Data Swamps) to something more in the middle.
We have already seen two-tier architectures with a Data Lake and a downstream Data Warehouse that take some of the data from the Data Lake and then bring structure to it. This means that data is first ETLed into the Data Lake and then ETLed again into the Data Warehouse, resulting in complexity and delays.
The promise of the Data Lakehouse is that of an one-tier architecture with better efficiency, flexibility, reusability and cost efficiency. That's not a small promise.
So if you haven't already, take a look at the Data Lakehouse!