Introduction to Azure Synapse Dedicated SQL pools (formerly SQL DW)
Azure Synapse is a super-scalable analytics service for enterprise data warehousing and Big Data analytics. It gives you two options: Dedicated SQL pool or Serverless on-demand resources. This article will describe the Dedicated SQL pool.
On the surface it may look similar to an ordinary SQL Database, but inside the Azure Synapse Dedicated SQL pools is a tremendously powerful Massively Parallel Processing (MPP) engine. Originally there was the SQL Server Parallel Data Warehouse (PDW) applicance, which cost in the $1 million USD range (depending on number of compute nodes). So, with the Azure Synapse Dedicated SQL pools you can get the potential capacity of a multi-million dollar server. First when introduced it was called Azure SQL DW (or SQL Data Warehouse), and you still see that name in some places, for example if you type SELECT @@VERSION.
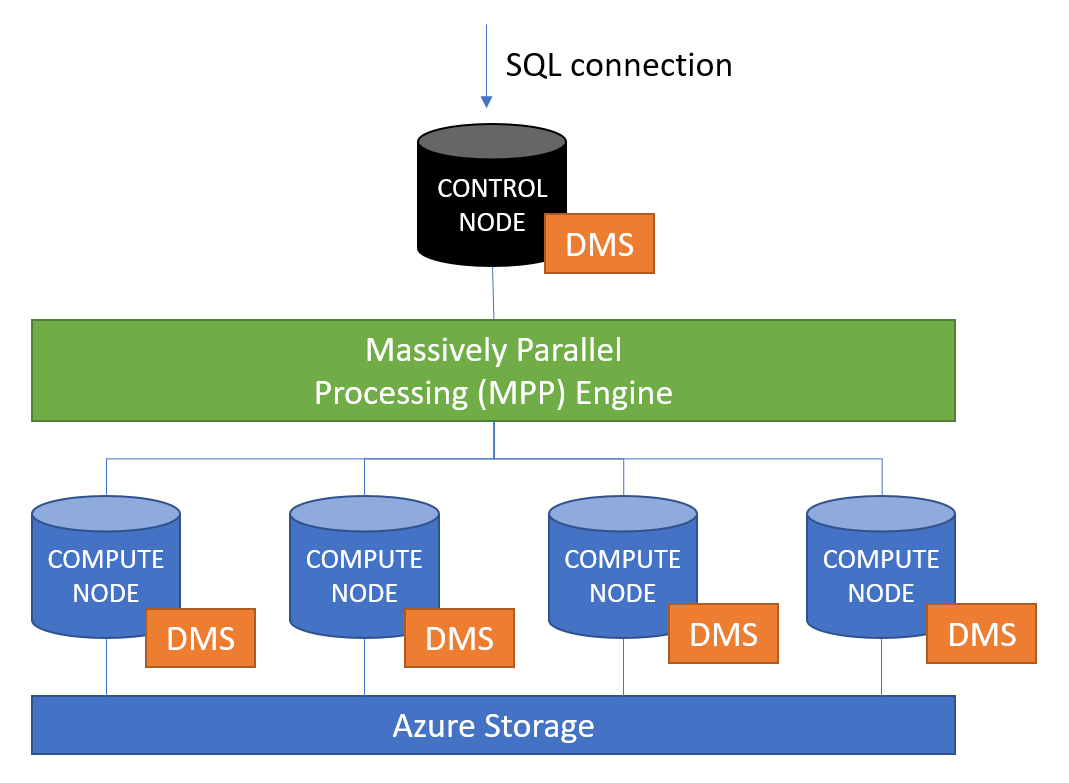
The figure describes the general architecture. Basically, the SQL queries (from users and applications) comes into the control node. The control node then distributes the query to the compute nodes and assembles the results. Data is transferred between nodes using the Data Movement Service (DMS).
Creating your first Azure Synapse Dedicated SQL Pool
You can easily create a Dedicated Pool like any other resource through the Azure Portal or through Azure Resource Manager. Just search for "sql pool", and it should appear in the list.
Pricing
The performance depends on the number of DWU units you choose (or cDWU as they are called). The current minimum is 100 DWU, which means you will get one compute node. At 200 DWU you will get two compute nodes (which gives you about twice the performance of a single compute node), and so on. Dedicated SQL pools splits your data into a minimum of 60 distributions (databases), which will get evenly distributed among your compute nodes. The current maximum is 30000 DWUs.
The price is currently around $1.20/hour for 100 DWUs. For 200 DWUs, it will be twice as much, and so on.
You can pause your Dedicated SQL Pool anytime to suspend costs (although you still pay for the storage) and then resume it again when you need it. So you can use it to process a batch of data and then pause it after you have finished. If you still need the data to be readable, you can scale down to 100 DWU:s instead of pausing.
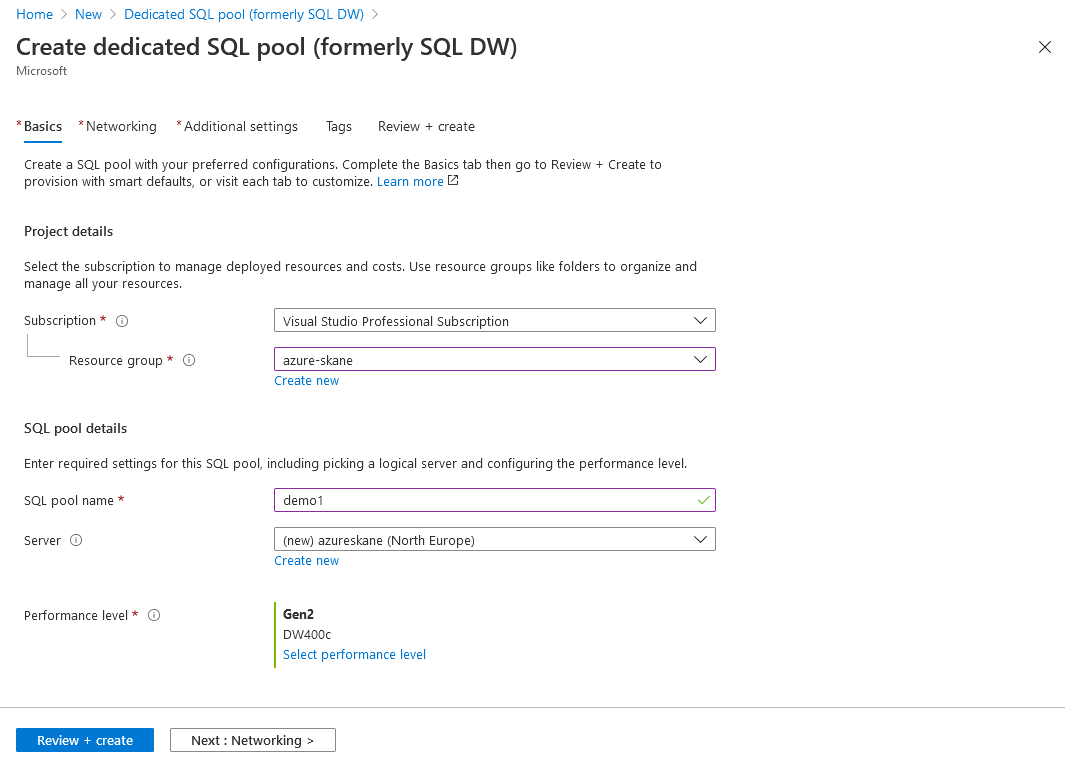
Options
The options are similar to creating an ordinary Azure SQL Database. You need to select a server (or create a new one) and you need to select the performance level.
Note that you easily can change the performance level later. For your first testing, I recommend starting with a minimum of 200 DWU:s, so you get at least 2 compute nodes.
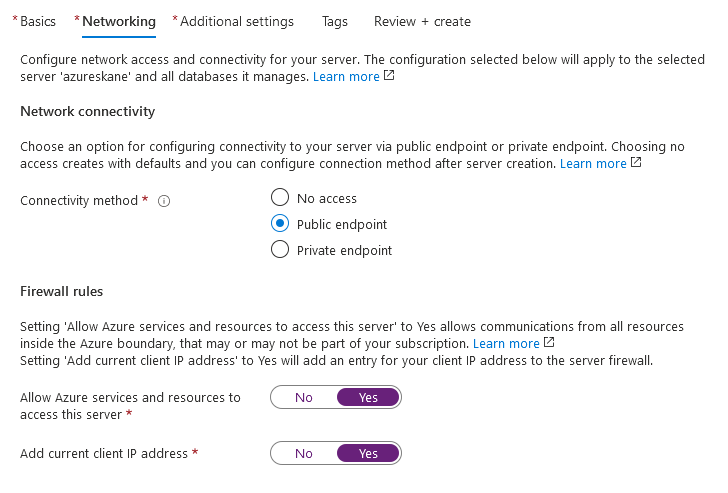
The next step is the Networking. It is probably easiest for you to test it if you choose a public endpoint. You can always change these settings later after the Dedicated SQL Pool has been created.
The most important setting is the SQL pool collation. This setting can't be changed later.
Finally done! Creating the SQL pool should not take more than 10 minutes.
Connecting
You can connect through the Azure portal, but my preferred way to connect to the Azure Synapse Dedicated SQL Pool is to use Management Studio. You can connect to the SQL Pool just like any database.
To test the connection you can select your database and run this command:
1SELECT @@VERSION
It should return something like "Microsoft Azure SQL Data Warehouse - 10.0.15554.0 Dec 10 2020 03:11:10 Copyright (c) Microsoft Corporation".
Creating your first billion rows
1CREATE TABLE dbo.Billion
2WITH (
3 DISTRIBUTION = ROUND_ROBIN
4 ,CLUSTERED COLUMNSTORE INDEX
5)
6AS
7WITH ten(a) AS
8(
9 SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
10)
11SELECT r = 1
12FROM ten AS t1 CROSS JOIN ten AS t2 CROSS JOIN ten AS t3 CROSS JOIN ten AS t4 CROSS JOIN ten AS t5 CROSS JOIN ten AS t6 CROSS JOIN ten AS t7 CROSS JOIN ten AS t8 CROSS JOIN ten AS t9;
Why all the "UNION ALL"? The T-SQL language in Dedicated SQL Pools has some limitations compared to single SQL databases. Therefore you can't (at least currently) run recursive CTEs or use a Table Value Constructor.
Note the settings DISTRIBUTION = ROUND_ROBIN and CLUSTERED COLUMNSTORE INDEX. We'll talk about these later.
Check the distribution of your rows
To check the space used and distribution of your rows, run this command:
1DBCC PDW_SHOWSPACEUSED('dbo.Billion');
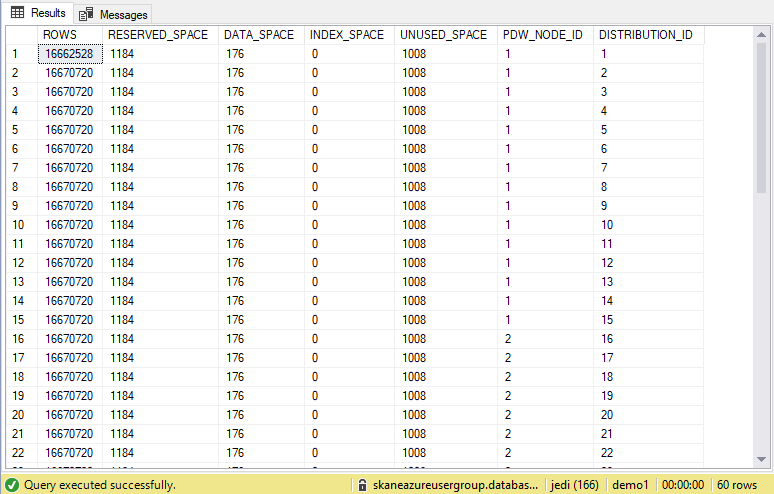
The first column shows the number of rows from your table. The RESERVED_SPACE tells you how many KBs are consumed. The PDW_NODE_ID tells you which node the data is stored on. Since we used ROUND_ROBIN distribution, the rows will be very equally distributed.
Workload Management
In a production environment, you probably wish to govern resources so they are distributed efficiently between users, ETL-tools, etc. You can govern the resources either from the Azure Portal or by T-SQL. For instance you can create a workload group for your ETL processes.
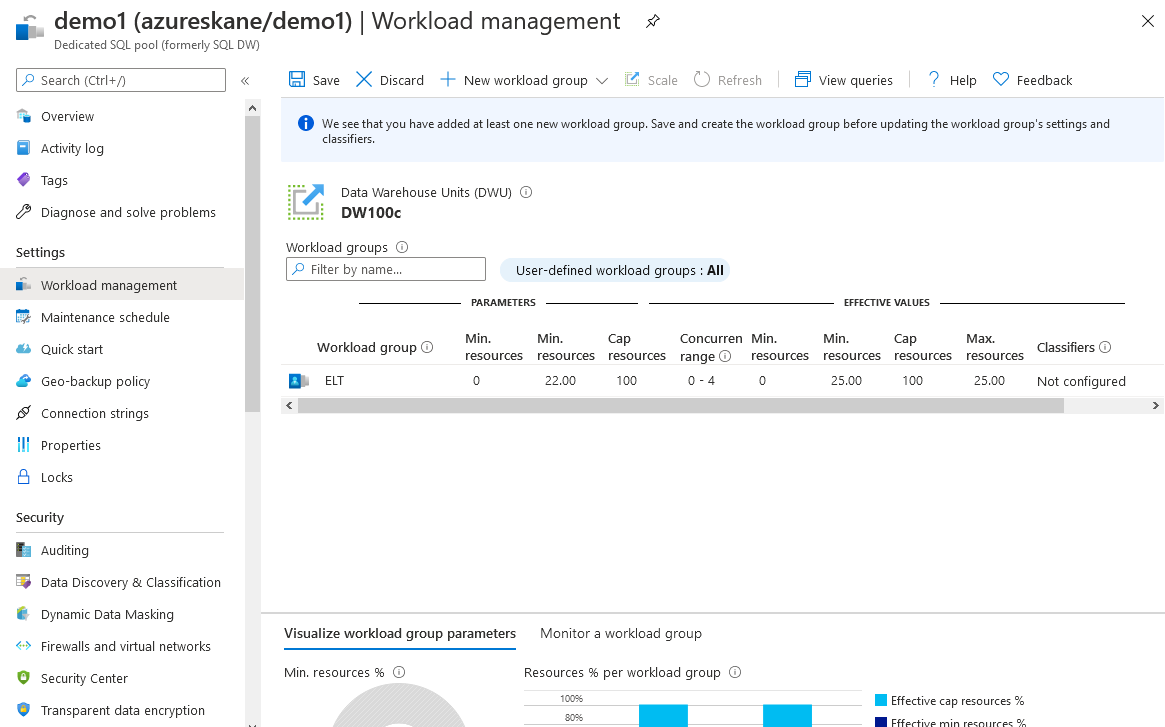
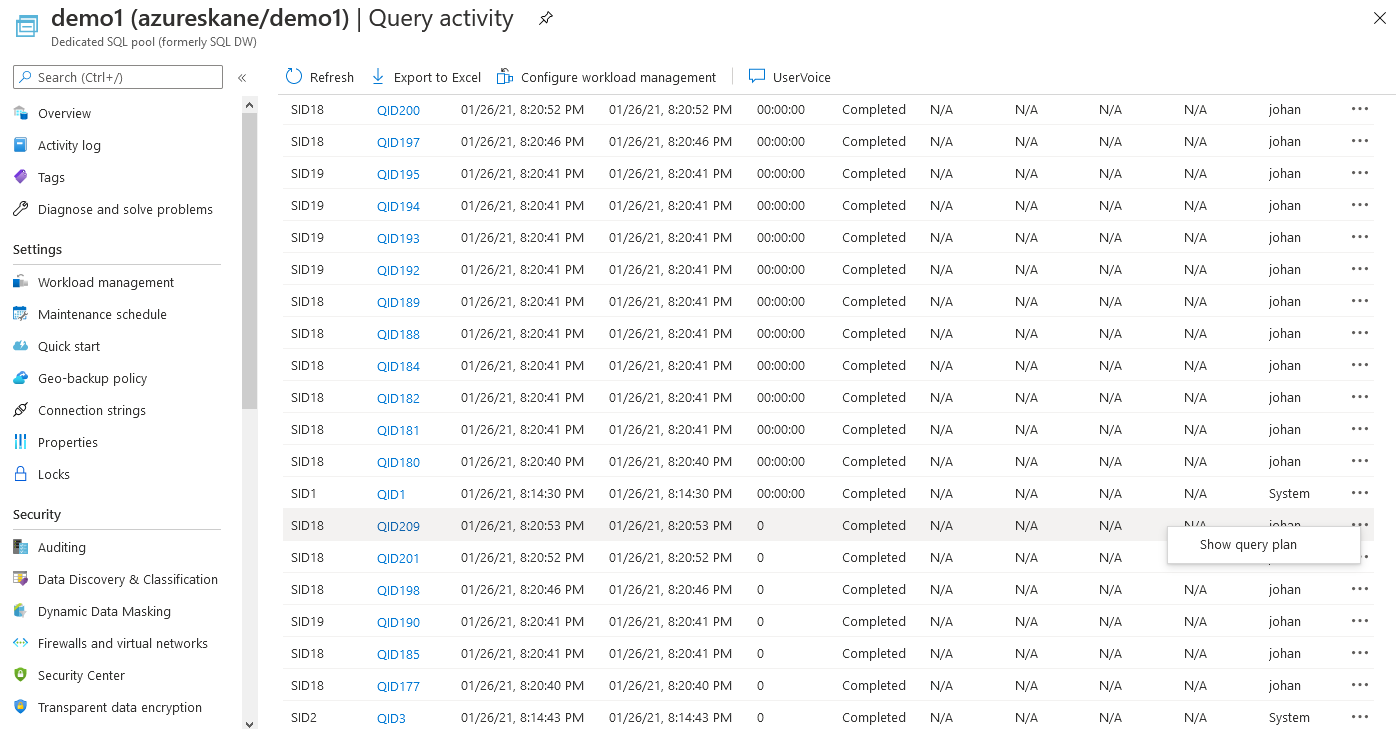
From the Workload Management page in the Azure Portal, you can also click "View Queries" to see current query activity. From there you can also view the query plans for your queries.
Distribution and table type
When you run the CREATE TABLE AS SELECT statement, you can choose distribution type and table type.
Distribution types:
- ROUND_ROBIN (table is spread evenly among the distributions)
- HASH (table is distributed using a hash key)
- REPLICATE (the whole table is copied to all nodes, which means it will take more diskspace)
In most cases you should use HASH for fact tables and REPLICATE for dimension tables. The choice of HASH key is very important.
Table types:
- CLUSTERED COLUMNSTORE INDEX
- HEAP
- CLUSTERED INDEX
The table types are the same as for ordinary SQL Server databases. HEAPS are usually the fastest for writes. CLUSTERED COLUMNSTORE INDEXES are usually fastest for reads.
Note that the MPP architecture doesn't allow PRIMARY KEYS or FOREIGN KEYS on your tables. Also IDENTITY columns should be avoided if possible.
Creating a fact table
Let's now create a fact table. We can use the previous table (dbo.Billion) as source to get a billing fact rows.
1CREATE TABLE dbo.Fact_Sales
2WITH (
3DISTRIBUTION = ROUND_ROBIN
4,CLUSTERED COLUMNSTORE INDEX
5)
6AS
7SELECT
8SalesID = a
9,SalesDate = DATEADD(DAY, b, CAST('2017-01-01' AS DATE))
10,CustomerID = b / 2
11,ChannelID = b / 50 + 1
12,Amount = CAST(b AS BIGINT)
13FROM dbo.Billion
14CROSS APPLY (
15SELECT a = NEWID()
16) AS ca1
17CROSS APPLY (
18SELECT b = CAST(CAST(a AS BINARY(1)) AS INT)
19) AS ca2;
Creating dimension tables
If you want more realistic dimension tables, you could upload some textfiles into BLOB Storage using and import into your SQL Pool using PolyBase T-SQL queries.
For simplicity, I will only use T-SQL to create our sample dimension tables.
1CREATE TABLE dbo.Dim_Customer
2WITH (
3DISTRIBUTION = REPLICATE
4,CLUSTERED INDEX (CustomerID)
5)
6AS
7WITH sixteen(i) AS
8(
9SELECT 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL
10SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL
11SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10 UNION ALL SELECT 11 UNION ALL
12SELECT 12 UNION ALL SELECT 13 UNION ALL SELECT 14 UNION ALL SELECT 15
13),
14twohundredfiftysix(i) AS
15(
16SELECT t1.i * 16 + t2.i
17FROM sixteen AS t1 CROSS JOIN sixteen AS t2
18)
19SELECT
20CustomerID = i
21,CustomerName = 'Customer ' + CAST(i AS VARCHAR(3))
22FROM twohundredfiftysix;
And the second dimension table:
1CREATE TABLE dbo.Dim_Channel
2WITH (
3DISTRIBUTION = REPLICATE
4,HEAP
5)
6AS
7SELECT
8ChannelID
9,ChannelName
10FROM (
11SELECT ChannelID = 1, ChannelName = 'Webshop' UNION ALL
12SELECT ChannelID = 2, ChannelName = 'Telemarketing' UNION ALL
13SELECT ChannelID = 3, ChannelName = 'Distributor' UNION ALL
14SELECT ChannelID = 4, ChannelName = 'Mailorder' UNION ALL
15SELECT ChannelID = 5, ChannelName = 'VIP store' UNION ALL
16SELECT ChannelID = 6, ChannelName = 'Educational'
17) AS t;
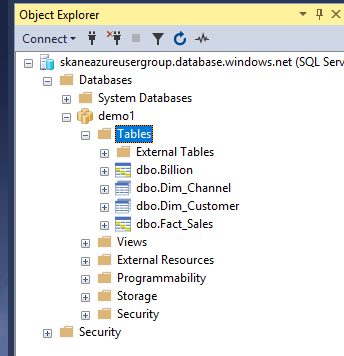
The whole list of tables should now look like this. Note that the icon is different on DISTRIBUTED tables than on REPLICATED tables.
Querying your data
You can now try your first query.
1SELECT COUNT(*) FROM dbo.Fact_Sales;
Let's also aggregate the Amount column.
1SELECT [Amount] = SUM(Amount), [Count] = COUNT(*) FROM dbo.Fact_Sales;
Finally, let's do some joins and GROUP BY.
1SELECT CustomerName, ChannelName, [Amount] = SUM(Amount), [Count] = COUNT(*)
2FROM dbo.Fact_Sales AS s
3JOIN dbo.Dim_Customer AS cu ON s.CustomerID = cu.CustomerID
4JOIN dbo.Dim_Channel AS ca ON s.ChannelID = ca.ChannelID
5GROUP BY cu.CustomerName, ca.ChannelName;
This last query will be a little slows the first time you run it because the replicated tables have to be copied to all nodes.
Using a BI client tool
Azure Synapse Dedicated SQL Pools support most BI tools, since it is mostly compatible with an ordinary SQL Server. It also supports loading the data into SQL Server Analysis Services (SSAS), which you could even run in Direct Query-mode to get real-time data and push the execution of query logic so it gets executed inside the SQL Pool.
With Power BI, it's very simple to connect. You just click Get Data, and then there is a connector in the Azure tab.
DMVs
There are many Dynamic Management Views (DMVs) for monitoring the progress and status of your queries.
You can show all running queries with this command (it gives the same information you can find in the Azure Portal if you click View queries):
1SELECT * FROM sys.dm_pdw_exec_requests;
Or you can get a list of your nodes by using this query:
1SELECT * FROM sys.dm_pdw_nodes;
References
- Azure Synapse Analytics Documentation
- Data loading
- Guidance for distributed tables
- Dynamic Management Views (DMVs)
- Pricing